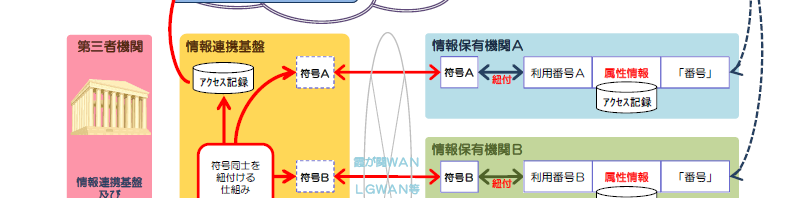
国民ID制度、「番号」制度(あやまって、共通番号制度とも呼ばれることがあるが)のコンテキストで語られるシステム基盤に、「情報連携基盤」とよばれるものがあります。下の図(内閣官房情報連携基盤技術ワーキンググループ中間報告より)のオレンジの箱がそれです。

どうもここの部分が、各界の「識者」の方々には、「複雑怪奇」「動かない」とか「ベンダーを利するだけ」などと何かと評判が悪いようです。
実際には、このような仕組みを入れることは、プライバシーやセキュリティの観点から不可欠で、これの理由も延々と報告書やら議事録やらに収録されているのですが、私の観点としては、(やり方に気をつけさえすれば)そもそも「複雑」ですらないので、まずそのことについて書きたいと思います。
インターネットって複雑怪奇で動かないシステム?
そこで、質問。
今、この記事をご覧になっているあなた、インターネットって複雑怪奇で動かないシステムだと思いますか?
そんなわけないですね。あなたがこの記事を見ることができているのが、何よりの証明です。
この記事を見るのに置きているステップをちょっと書きだしてみましょう。
- (記事に対するリンクをふむなどして)この記事の「番号」(=http://www.sakimura.org/2011/08/1223/)を指定する。
- ブラウザがこれを、http と www.sakimura.org(情報の取得先) と /2011/08/1223/ (取得先でのこの記事の番号)に分解する。
- www.sakimura.org を DNS に問い合わせて、IPアドレスに変換する。
- このIPアドレスの80番ポートを宛先にして通信を開始する
- (以下、ルーティング、宛先のルータでのIPアドレスのMACアドレスへの変換などいろいろ)
- 通信が確立すると、GET /2011/08/1223 HTTP/1.1 などのコマンドを送る。
- このページのHTMLソースが返却される。
- ブラウザがこのHTMLソースを解析し、図などが挿入されていたら、上記と同じプロセスを通じてそれらも取得する。
- 取得した結果を評価、表示する。
まぁ、ものすごく簡略化して書くと、こんなものです。
これに対して、同じようなレベルで情報連携基盤がやっていることを書くと、こんなふうになります。(以下は、2つ検討されている方式の中の「アクセストークン方式」と呼ばれるものです。)
- 情報を取得したい個人のアドレス「符号A」と、ほしい情報を指定する。
- 「符号A」とほしい情報の組み合わせを「情報連携基盤」に問い合わせて、「情報の取得先」と「符号A」に対応する「中間アドレスA」を取得する。
- 「情報の取得先」に「中間アドレスA」を送信する。
- 「情報の取得先」は、「中間アドレスA」を「情報連携基盤」に問い合わせて「符号B」と「ほしい情報一覧」を取得する。
- 「情報の取得先」は、「符号B」に対応する「ほしい情報」を作成して、返却する。
これのどこが複雑怪奇なのでしょうか?
更に、あなたが最近のWeb技術に明るい技術者なら、すでにもうぴんと着ているはずです。
「あ、これ、OAuth 2.0とおんなじ流れだな。」
OAuth 2.0 は、現在IETFで標準化が進んでいる情報連携技術で、世界の趨勢としてはこれが主流になる見込みです。「単純」「簡明」「簡単」で有名なこのプロトコルを「複雑怪奇」と呼んでは、良識を疑われます。
ちなみに上記を、OAuth 2.0語に翻訳するならば、こうなります。
- 情報を取得したい「リソース」と「スコープ」を指定する。
- 「リソース」と「スコープ」に対するアクセス認可を「認可サーバ」に問い合わせて、「リソース」と「スコープ」に対応する「アクセストークン」を取得する。
- 「リソース」に「アクセストークン」を送信する。
- 「リソース」は、「アクセストークン」を「認可サーバ」に問い合わせて「実際に返却すべき情報の一覧」を取得する1。
- 「リソース」は、「返却すべき情報」を作成して、返却する。
ほぼ、同じでしょう?実際、私は、この仕組はOAuth 2.0 で実装できると思っています2 。
「いやいやそんなことはない。民間のシステムと違って、1億2千万人を対象にする、超大規模システムなのだ!」とおっしゃる向きもおられるかもしれませんが、それに対しては、こう答えましょう。
「Googleで2億人、Facebook で6億人がこうしたシステムで動いています。1億2千万人は特に大きなシステムではない。まして、トランザクション量にいたっては、国のシステムなど微々たるものだ。」
で、結論です。
(図1)に示した「情報連携基盤」は「複雑怪奇」でも「動かない」システムでも無い。むしろ、技術的には、「簡単」「簡明」「単純」なシステムでありうる。
ん、「ありうる」?
そうです。情報連携基盤技術ワーキンググループでは、要件/ポリシーを定めているだけで、具体的な設計については一切言及していません。(今の段階で言及すべきではないでしょう)。何事も、やり方は一つではありません。OAuth2.0 みたいに単純にやることもできれば、それこそ「複雑怪奇」な実装設計をすることもできるでしょう。行うべきは、後者のようなことにならないように目を光らせることであって、図1を見た印象で「複雑怪奇」とか叫ぶことではないのですよ。