前回、「マイナンバーとプライバシー:識別子に対する要件」で、以下のように書きました。
次に、仮想例として、税と社会保障(含む年金)の共通番号というものを考えてみましょう。これは、基礎年金番号と納税者番号双方の要件を満たす必要が出ます。つまり、年金管理が要求する「長い期間」と、税が要求する「広い範囲」の掛け算が必要になります。つまり「長い期間広い範囲で安定的」な識別子が必要になります。これは、要件3を満たしませんので、筋の悪い組み合わせだと言えます。
今回はこれを素材として、識別子のもたらすリスクの特性について考えたいと思います。
識別子の種類
さて、まず本題に入る前に識別子の定義を復習し、その種類をまず見てみましょう。
識別子:=ある集団の中で、その個人(やモノ)を一意に他と区別(識別)うることができる属性の組み合わせ
そうです。普通に考える「個人番号」のようなものだけでなく、「氏名・性別・生年月日・住所」(基本4情報)のようなものも識別子なのでした。
これらの分類にあたっては、今回は、「利用範囲」「利用期間」「再利用性」の3種類を使います。「利用範囲」はどれだけの人・企業・団体などがその識別子を使うか、「利用期間」は、どれだけの期間その識別子が使われるか、「再利用性」はその識別子が他の人に対して再利用されることがあるかどうかです。
- 無指向性識別子 (omnidirectional identifier):相手に関係なく用いられる識別子
- 単一指向性識別子 (directional identifier, sectoral identifier):相手との関係性の中のみで使われる識別子
- 継続的識別子 (persistent identifier):長期間変わらない識別子。通常、その実体が存在する限り不変。
- 短期識別子 (ephemeral identifier):短期間で変わる識別子。
- 再利用可能識別子 (reassignable identifier):他の実体に対して再利用される識別子。
- 再利用不能識別子 (non-reassignable identifier):再利用されない識別子。
期間×範囲でとらえる識別子の名寄せリスク
プライバシー侵害のリスクは、様々なことに起因します。たとえば、新聞などでよく報道される「情報漏えい」などは代表的なものです。しかし、ここでは「名寄リスク」を主要なものとして取り上げます。なぜならば、本当のところは「情報漏えい」自身がプライバシーにまつわる実際の被害を起こすのではなく、漏洩した情報をもとに他の情報(例えば被害者の知人が持っている事前知識)と「名寄せ(リンク)」して、本人の望まない「本人像」が形成されることこそが被害を生むからです。たとえ情報が漏洩しても、それが誰の目に触れることもなく海のそこにでも沈んでしまえば、ほとんどリスクは無いのです。
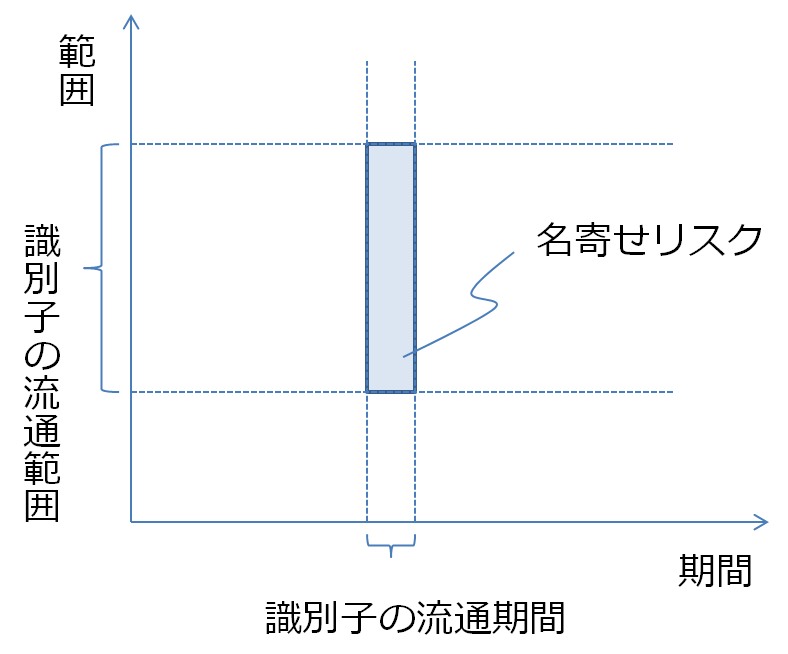
識別子による名寄のリスクの一面は、次の図のように期間×範囲の面積でとらえることができます。

横軸がその識別子が流通する期間、縦軸がその識別子が流通する範囲です。期間は、その識別子がどのくらいの期間にわたって利用されるか、範囲はどこまで利用が広がるかです。たとえば、webのcookieは、そのサイトでしか利用されませんから、流通範囲は極めて狭いと言えます。いわゆるセクトラル方式の識別子も、そのセクターでしか使われませんから狭いと言えます。一方、米国のSSNなどは、いたるところで利用されますから、識別子の流通範囲は広くなります。
図1では、識別子の流通期間は長いけれども、識別子の流通範囲は狭いものを図にしています。年金番号などはこのようなタイプの識別子です。これに対して、図2は、逆に、識別子の流通期間は短いけれども、流通範囲は広いという識別子の例を表しています。たとえば、年ごとに変わる税番号などはこのたぐいのものになります。

こうした識別子を併用した場合のリスクは、それぞれの場合のリスクの和です。

一方、識別子を統合した場合には次の図のようになり、統合せずに併用した場合よりもリスクが増えてしまいます。利用目的を、別々だった時のそれぞれの用途に限るとメリットは変わらないので、この増分がはメリットなきリスク増加と言えます。これを超過リスクと呼ぶことにします。

「税と年金の共通番号は筋が悪い」としたのは、このように超過リスクが生じてしまうからです。
連携のコスト
さて、このように超過リスクが生じてしまう方式を推進する人がいるのはなぜでしょうか?おそらくは「連携にはコストがかかる」というものでは無いかと思います。このコストには、業務上のコストとシステム上のコストの2種類があると思われます。
まず業務上のコストですが、これは連携だと上がってしまうのでしょうか?
もともと業務は個別の番号/識別子で遂行されていたはずです。であれば、連携にしたからとてコストが上がるとは思えません。適切に「範囲」を設定すればすむ話です。(これが、セクトラル方式においては、セクターの定義が重要と言われるゆえんです。)
次にシステムコストを見てみましょう。確かに統合してしまえば、異なる識別子を変換する手間はなくなりますから、その分は安くなります。では、どの位安くなるのでしょうか?ちょっと変換コストを弾いてみましょう。
Doing aes-128 cbc for 3s on 16 size blocks: 21715758 aes-128 cbc’s in 3.00s
結論
- 性質の違う識別子を統合してしまうと、名寄せに関して大きな超過リスクが生じる。
- 連携のコストは非常に安く、超過リスクを正当化することにはならない。
- したがって、税・年金共通番号はスジが悪い。
(脚注)
- 本当はCBCではなく、GCMなどのAEADアルゴリズムでやるべき。CBCだと integrity を付けなければならなく、このコストが割にバカにならない。hmac(md5)で、約240万個/秒・CPUしかできない。
- それどころか、超過リスクを制御するために様々なセキュリティ対策を行うことに比べたら圧倒的に安いことであろう。
- ま、もっとも、番号制度に関しては、リスク検討以前に、何をやりたいか、つまり「目的」の議論が必要ですが。目的が定まらなければ、そのリスクは取るべきリスクなのかどうかも良くわかりません。たとえば、行政手続コストを1/2にとか、そういう分かりやすい「目的」が必要だと思うんですけどね。
興味深く読みました。
連携を始めるための業務上のコストに、識別子間のマッピングテーブルを作るコストがあるように思われ、触れておいた方が良いような気がします。またそれ以上に、連携しようとすると番号/識別子は個人情報なので、連携に利用してよいかどうかの本人同意を取る必要があると思われ、この業務コストがとてもとても大きな気が。
とはいうものの、前者は、正規化された氏名、生年月日、住所の町名ぐらいまでがあれば共通番号があったからといってさしてマッピングテーブル作成の負担が減るわけでもないような気がするし、後者はそもそも共通番号の話でないので、よくよく考えれば、本質的には結論は変わらないような気もします。
識別子間のマッピングのコストは、統合識別子にしても連携識別子にしてもほぼ同じだけかかります。なので、ここの議論では捨象しています。マッピングに関しては、別エントリ(共通番号/マイナンバーの保管と紐付け作業について http://www.sakimura.org/2012/03/1558/ )で詳しく論じています。
また、「またそれ以上に、連携しようとすると番号/識別子は個人情報なので、連携に利用してよいかどうかの本人同意を取る必要があると思われ、この業務コストがとてもとても大きな気が。」に関してですが、結論から言うと関係ない議論です。統合識別子にしても連携識別子にしても必要になる同意は全く一緒です。いや、むしろ統合識別子の同意要求の方が「共有」であるだけに強烈です。そして、マイナンバー関連で言うならば、それは「法=社会的同意」で解決しようとしています。
なので、本質的にもなにも、結論も議論の過程も全く変わりません。
おっしゃられたようなことはもちろん考慮済みの上で書いています。
むしろ質問したいのですが、統合識別子を使ったときはどうして同意は必要ないと思われたのでしょうか?
統合識別子を使った時に同意が必要ないと思ったのは、私の中では、統合識別子とマイナンバー法案が一体としてとらえられていて、
①統合識別子+同意を不要とする法制定
②統合識別子(同意を不要とする法制定無し)
③連携識別子+同意を不要とする法制定
④連携識別子(同意を不要とする法制定無し)
のうち、①と④だけしか思い浮かばなかったからです。②も③も頭のなかにありませんでした。
最初それでコメントを書き始めたのですが、コメントを書きつつ、上記のようなことをぼやっと考えつつ(それほど整理できてませんでしたが)、「本質的には結論は変わらないような」でとりあえず書き終えたという経緯です。自己弁護ぽくなりますが、多くの人は同じように、③の選択肢に気付いてないのではないでしょうか。
識別子間のマッピングコストについては、リンク先の連携基盤の仕組みは上記の文脈から思い至らず、「番号」の選択肢として統合識別子と連携識別子の可能性があるとして
①統合識別子(番号)を用いて符号で連携
②統合識別子(番号)を用いて統合識別子そのもので連携
③連携識別子(番号)を用いて符号を用いず連携識別子間のマッピングで連携
④連携識別子(番号)を用いて符号で連携
の選択肢がある中で、②と③の比較だと思ったしだいです。プライバシーリスクを下げるために②は除外するが当然だとすれば、残りはなんらかマッピングが必要なので、業務負担的にはそんなに違いがないという理解ができます。
リンク先の議論の前提と異なって、基本4情報ではなく、統合識別子にしろ連携識別子にしろ番号が分かれば簡単に連携基盤から符号が入手できる前提で考えています。
上記のようなことを考えてはみたものの、「識別子間のマッピングのコストは、統合識別子にしても連携識別子にしてもほぼ同じだけかかります」の理解としてあっているのかどうかかなり不安な状況です。
②にしたとしても、統合識別子と既存のアカウントのマッピングはどうしても必要になります。なので、そこのコストは掛かってしまうんです。
理解しました。
ありがとうございます。
私が疑問に思ったような内容の解説調の記事をそのうち書いてもらえるとうれしいです。
世の中ほとんど、統合識別子(共通番号)を導入して、連携基盤の符号変換みたいな複雑なことをしなければ、簡単に連携できるようになると誤解していると思いますので。一般的な人の直感とかけ離れているので、よほどうまく説明しないと納得してもらえないような気がしています。
優先順位が高いかどうかもありますし、お忙しいと思いますので、お聞き流しください。